JOINT AUDIO-VIDEO DRIVEN FACIAL ANIMATION
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018 [Oral]
Xin Chen, Chen Cao, Zehao Xue, Wei Chu
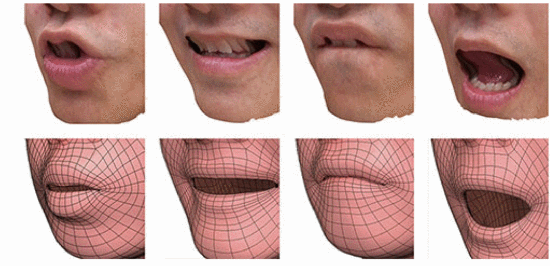
Automatic facial animation is a research topic of broad and current interest with widespread impact on various applications. In this paper, we present a novel joint audio-video driven facial animation system. Unlike traditional methods, we incorporate a large vocabulary continuous speech recognition (LVCSR) system to obtain phoneme alignments. The use of LVCSR reduces the high error rate associated with the traditional phoneme recognizer. We also introduce a knowledge guided 3D blendshapes modeling for each phoneme to avoid collecting training data and introducing bias from computer vision generated targets. To further improve the quality, we adopt video tracking and jointly optimize the facial animation by combining both sources. In the evaluations, we present both objective study and several subjective studies on three settings: audio-driven, videodriven, and joint audio-video driven. We find that the quality of our proposed system’s facial animation generation surpasses that of the recent state-of-the-art systems.
[PDF]
3D HAND SHAPE AND POSE ESTIMATION FROM A SINGLE RGB IMAGE
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019 [Oral]
Liuhao Ge, Zhou Ren, Yuncheng Li, Zehao Xue, Yingying Wang, Jianfei Cai, Junsong Yuan

This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
